Дизайн OpenCL
В статье рассматриваются основные принципы дизайна OpenCL согласно стандарту версии 1.1. Не вдаваясь в излишние на данном уровне изложения подробности описаны 4 модели, на которых держится стандарт: модель платформы, модель исполнения, модель памяти и модель программирования. В статье не приведено ни единой строчки программного кода, так как цель - лишь ввести читателя в мир разработки на OpenCL, осветив различные стороны его дизайна.
Введение
OpenCL - индустриальный стандарт, рожденный в 2008 году в результате взаимодействия специалистов компании Khronos Group с разработчиками программного обеспечения, вендорами аппаратных решений (в том числе мобильных платформ) и производителями процессоров различных типов и назначений. Центральная идея OpenCL - предоставить программисту универсальный инструмент для использования всех вычислительных мощностей современных вычислительных систем.
По задумке авторов, написав однажды программу с использованием OpenCL, можно будет запускать ее практически на любой вычислительной системе: телефонах, графических картах, ускорителях и т.п. Насколько качественно составители стандарта сумели воплотить эту идею - тема отдельной дискуссии. Но определенно сейчас можно сказать одно - данный стандарт явился важным шагом в развитии параллельного программирования для гетерогенных систем.
Созданные на OpenCL программы потенциально могут использовать имеющиеся ресурсы вычислительной системы следующим образом:
- определить доступные ресурсы в гетерогенной системы и выбрать подходящие;
- создать последовательность инструкций, которые будут выполняться на ресурсах;
- подготовить начальные данные для вычислений;
- заставить эти ресурсы выполнить OpenCL-инструкции, обрабатывающие подготовленные данные;
- собрать результаты вычислений.
Для понимания как OpenCL помогает выполнить описанные выше действия рассмотрим OpenCL-приложение с четырех точек зрения.
Модель платформы
Модель платформы (platform model) дает высокоуровневое описание гетерогенной системы.
Центральным элементом данной модели выступает понятие хоста (host) - первичного устройства, которое управляет OpenCL-вычислениями и осуществляет все взаимодействия с пользователем. Хост всегда представлен в единственном экземпляре, в то время как OpenCL-устройства (devices), на которых выполняются OpenCL-инструкции могут быть представлены во множественном числе. OpenCL-устройством может быть CPU, GPU, DSP или любой другой процессор в системе, поддерживающийся установленными в системе OpenCL-драйверами.
OpenCL-устройства логически делятся моделью на вычислительные модули (compute units), которые в свою очередь делятся на обрабатывающие элементы (processing elements). Вычисления на OpenCL-устройствах в действительности происходят на обрабатывающих элементах. На рис. 1 схематически изображена OpenCL-платформа из 3-х устройств.
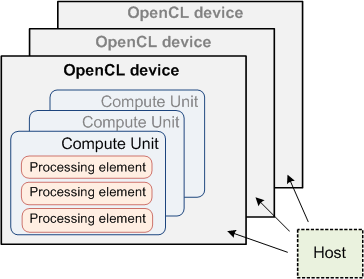
Рис. 1: Схематическое представление OpenCL-платформы.
Модель вычислений
Модель вычислений (execution model) описывает абстрактное представление того, как потоки инструкций выполняются в гетерогенной системе.
С хостом неразрывно связано понятие хостовой программы (host program) - программного кода, выполняющегося только на хосте. OpenCL не указывает как именно должна работать хостовая программа, а лишь определяет интерфейс взаимодействия с OpenCL-объектами.
С точки зрения модели вычислений OpenCL-приложение состоит из хостовой программы и набора ядер (kernels). OpenCL-ядро в общем виде представляет собой функцию, написанную на языке OpenCL C (подмножество языка ISO С’99) и скомпилированную OpenCL-компилятором.
Ядро создается в хостовой программе и затем с помощью специальной команды ставится в очередь на выполнение в одном из OpenCL-устрйоств. Во время выполнения упомянутой команды OpenCL Runtime System создает целочисленное пространство индексов (integer index space), каждый элемент которого носит название глобальным идентификатором (global ID). Каждый экземпляр ядра выполняется отдельно для каждого значения глобального идентификатора. Экземпляр ядра носит название work-item. Таким образом, каждый work-item однозначно определяется своим глобальным идентификатором.
Множество всех work-item разбивается на группы. Такая группа носит название work-group. С каждой work-group сопоставляется свой уникальный идентификатор (work-group ID). Все work-item в одной work-group идентифицируются уникальным в пределах своей группы номером: local ID. Таким образом каждый work-item определяется как по уникальному global ID так и по комбинации work-group ID и local ID внутри своей группы.
Все work-item в пределах одной work-group выполняются параллельно на обрабатывающих элементах одного вычислительного модуля OpenCL-устройства. Это гарантируется стандартом, в то время как совершенно не гарантируется, что несколько work-item из разных групп будут выполнены параллельно. Об этом важном свойстве параллелизма необходимо всегда помнить при разработке OpenCL-программ.
Пространство индексов N-размерно и обычно носит название NDRange. В случае версии стандарта OpenCL 1.1 размерность N принимает значения 1,2 или 3. Таким образом, сетки координат global ID и local ID N-размерны, т.е. определяются N координатами. На рис. 2 схематически показан двумерный NDRange.
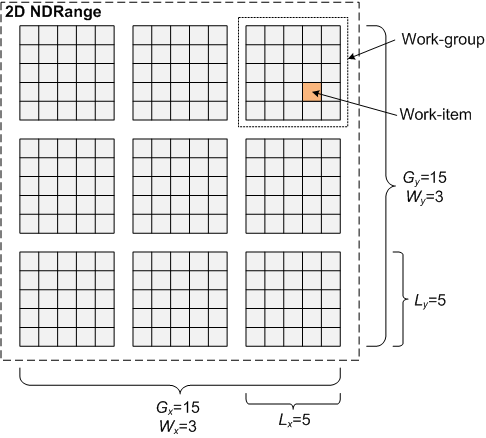
Рис. 2: Пример двумерного NDRange,
где Gx и Gy - число глобальных идентификаторов,
Wx и Wy - число групп, а Lx и Ly - число локальных идентифкаторов в NDRange.
Другим важным понятием модели вычислений является контекст, определение которого (при помощи вызова специальных функций OpenCL API) является первой задачей OpenCL-приложения. Контекст определяет среду выполнения ядер, в которую входят следующие компоненты: устройства, сами ядра, программные объекты (program objects, исходный и выполняемый код будущих ядер), объекты памяти (memory objects).
Взаимодействие между хостом и OpenCL-устройством происходит посредством команд, помещенных в командную очередь (command-queue). Данные команды ожидают в командной очереди своего выполнения на OpenCL-устройстве. Командная очередь создается хостом и сопоставляется одному OpenCL-устройству после того, как будет определен контекст. Команды делятся на те, что отвечают за: выполнение ядер, управление памятью и синхронизацию выполнения команд в очереди. Команды могут выполняться последовательно (in-order execution) или внеочередно (out-of-order execution). Второй вариант организации очередей поддерживается не всеми платформами, о чем необходимо помнить.
Модель памяти
Модель памяти (memory model) описывает набор регионов памяти и манипулирование ими во время проведения вычислений.
OpenCL-объекты, инкапсулирующие регионы памяти, носят название объектов памяти (memory objects). Объекты памяти бывают двух типов: буферные объекты (buffer objects) и объекты изображения (image objects).
Буферные объекты памяти инкапсулируют непрерывные участки памяти, доступные ядрам во время выполнения. Программист обычно производит отображение структур данных на данные объекты, а в коде ядра получает доступ к данным структурам посредством указателей.
Объекты изображений ограничены хранением изображений. При этом как именно изображение хранится не определяется стандартом и скрыто от программиста. Обычно хранение и доступ к изображению оптимизирован под конкретную аппаратную платформу.
Стандарт описывает следующие пять различных регионов памяти.
- Память хоста (host memory) доступна лишь с хоста.
- Глобальная память (global memory) определяется в памяти, доступной на чтение и запись для всех work-item во всех work-group. Чтение и запись в глобальную память может кешироваться, если OpenCL-устройство поддерживает данную возможность. В случае CPU глобальной является оперативная память. В подавляющем большинстве случаев глобальная (и константная) память самая медленная, так что использовать без необходимости ее не стоит.
- Константная память (constant memory) - глобальный регион памяти, который инициализируемые хостом и из которого work-item может лишь читать данные.
- Локальная память (local memory) доступна лишь в пределах одной work-group. Все work-item в данной work-group могут как читать, так и писать в данный регион памяти одновремено.
- Приватная память (private memory) доступна лишь одному work-item.
На рис. 3 показаны отношения между перечисленными регионами памяти согласно стандарту OpenCL.
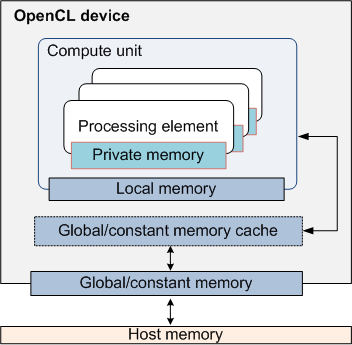
Рис. 3: Схематическое представление нескольких уровней памяти в OpenCL.
Модель программирования
Модель программирования (programming model) описывает варианты переноса абстрактного алгоритма на гетерогенные вычислительные ресурсы.
OpenCL определяет два типа модели программирования: параллелизм по данным (data parallelism) и параллелизм по заданиям (task parallelism).
Параллелизм по данным
Данный тип модели программирования организован вокруг структур данных: каждый элемент определенной хостом структуры данных обновляется одновременно (параллельно) копиями одного и того же OpenCL-ядра. Дизайн такой структуры должен поддерживать возможность одновременного изменения различных её частей.
Модель параллелизма по данным наиболее естественная модель программирования для OpenCL, так как NDRange создается непосредственно перед запуском ядра на устройстве. Задача программиста здесь описать решаемую задачу в терминах упомянутой структуры данных, отобразив ее на NDRange и инкапсулировав ее в объекте памяти.
В случае, если между несколькими work-item необходимо взаимодействие, то программист проектирует свой алгоритм с учетом разбиения множества всех work-item на некоторое количество work-group, в рамках которых несколько work-item могут осуществлять такое взаимодействие. Взаимодействие может осуществляться либо через чтение\запись локальных регионов памяти, либо через синхронизацию посредством группового барьера (work-group barrier).
Если групповой барьер определен в коде ядра, то все work-item в пределах одной work-group должны дойти до этого барьера прежде чем все work-item в этой группе перешагнут барьер и продолжат своё выполнение. Примером задачи, где может понадобится такая синхронизация служит суммирование элементов массива. Ввиду ориентированности технологии OpenCL на широкий круг устройств программисту необходимо учитывать, что OpenCL не поддерживает механизмы синхронизации между несколькими work-item из разных work-group.
Также необходимо помнить не только о том, что все work-item в пределах work-group выполняются одновременно, но и о том, что несколько work-group могут выполняться параллельно, если устройство такую возможность предоставляет. Таким образом, стандарт OpenCL описывает иерархическую модель параллелизма по данным: внутри каждой группы и между различными группами.
При проектировании алгоритма программист имеет две возможности относительно определения work-group. Первое (explicit model) - определить размер групп самостоятельно. Второе (implicit model) - предоставить возможность разбиения на группы непосредственно самой системе.
Параллелизм по заданиям
В стандарте OpenCL под заданием понимается ядро, выполняемое как единственный work-item. При этом вместе с таким заданием в устройстве могут одновременно выполняться и другие work-item. Необходимость параллелизма по заданиям может возникнуть, если параллелизм уже заключен в самом задании. Например, если в ядре задания производятся векторные операции над векторным типом данных.
Также данный тип модели программирования может возникнуть когда несколько команд запуска ядер помещаются в очередь в которой запуск происходит сразу же как команда в нее поместилась. В ряде случаев это позволяет увеличить степень использования OpenCL-устройств, позволяя системе самостоятельно планировать запуск множества различных заданий. Напомним, что параллелизм по заданиям с внеочередным запуском может не работать на некоторых вычислительных платформах и данный вариант модели программирования является скорее опциональной возможностью OpenCL.
Третий вариант параллелизма по заданиям возникает, когда множество заданий зависимо между собой и объединяются в граф с применением OpenCL-событий. Одни команды, помещенные в очередь могут генерировать события, а другие команды могут ожидать этих событий, что бы начать своё выполнение.
Выводы
Ограничения на синхронизацию между несколькими work-item в различных work-group, а также выборочная поддержка устройствами внеочередного выполнения команд из очередей очевидно снижает возможность перенесения алгоритмов из мира CPU на рельсы OpenCL. С развитием аппаратного обеспечения данные ограничения скорее всего исчезнут, что должно отразится в следующих стандартах OpenCL.
Материал по большей части представляет собой переработанный перевод первой главы книги "OpenCL Programming Guide / Aaftab Munshi, Benedict R. Gaster, Timothy G. Mattson, James Fung, Dan Ginsburg / Addison-Wesley - 2011".